For finding terms with greatest difference in between topics
Examples
lda <- SegmentR:::test_data(explore = FALSE)$lda$lda[[1]]
#> Making DTMs
#> making tuning grid
#> setting up LDAs
lda |> diff_terms_segmentr()
#> $topic1_vs_topic2
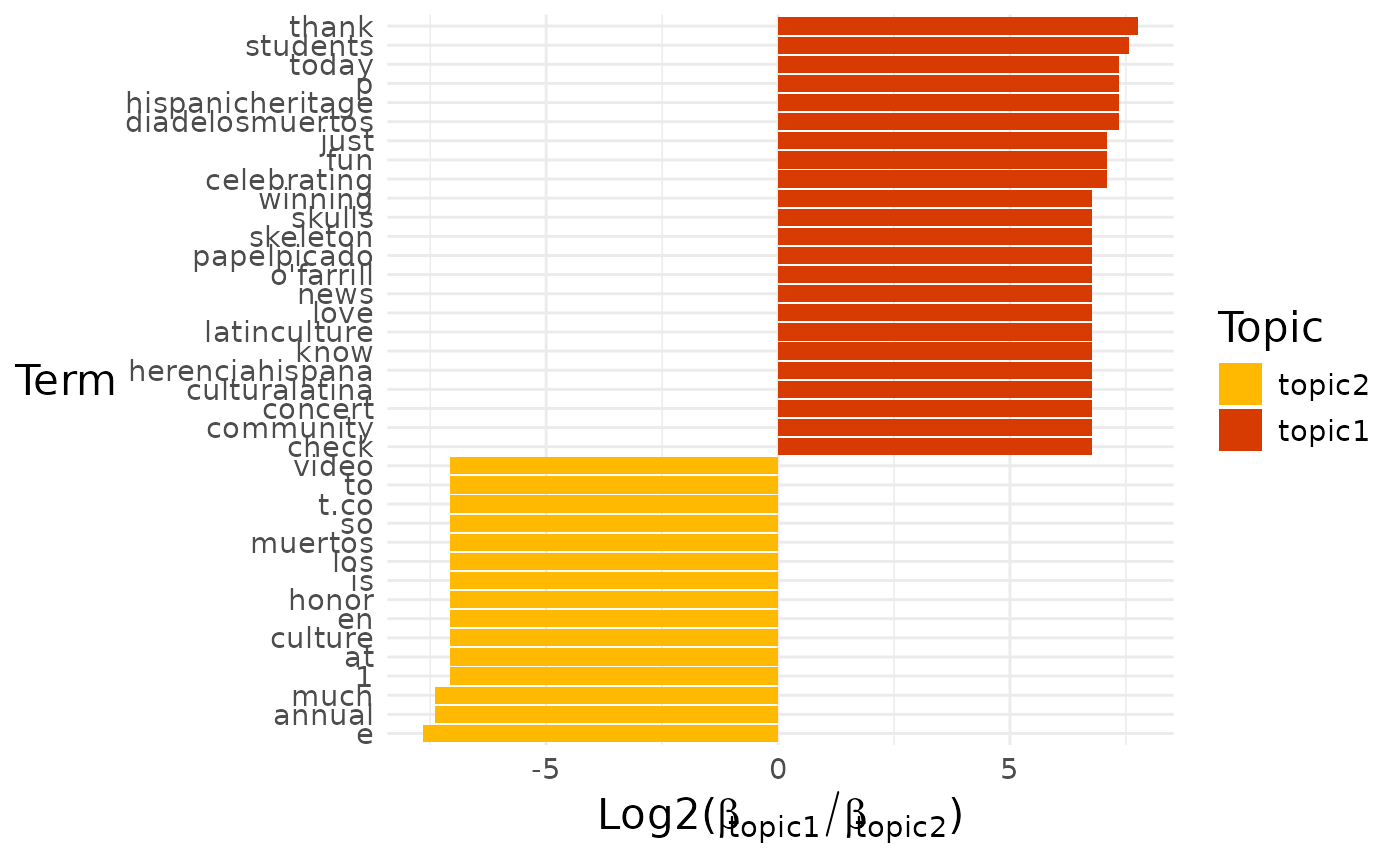 #>
#> $topic1_vs_topic3
#>
#> $topic1_vs_topic3
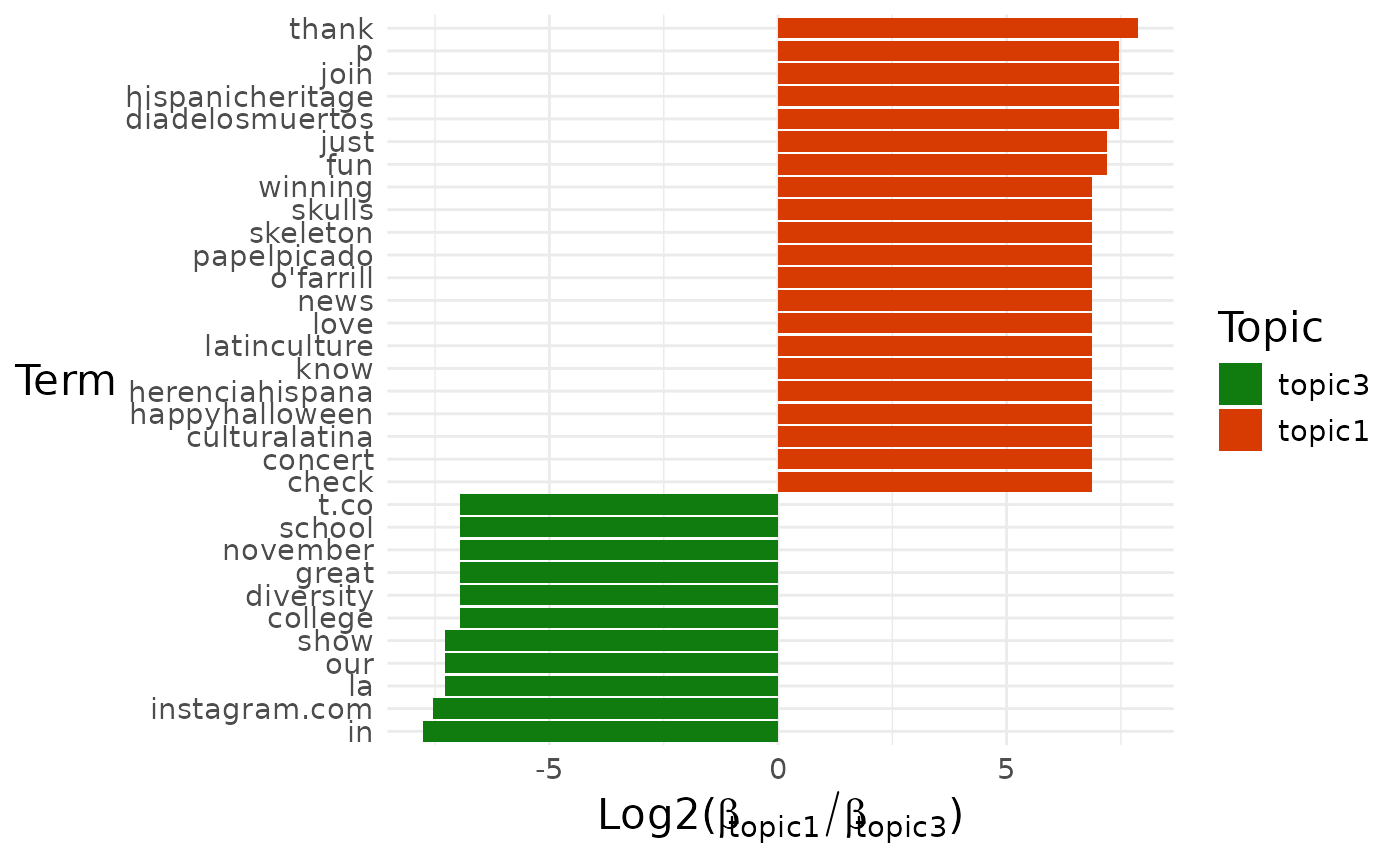 #>
#> $topic2_vs_topic3
#>
#> $topic2_vs_topic3
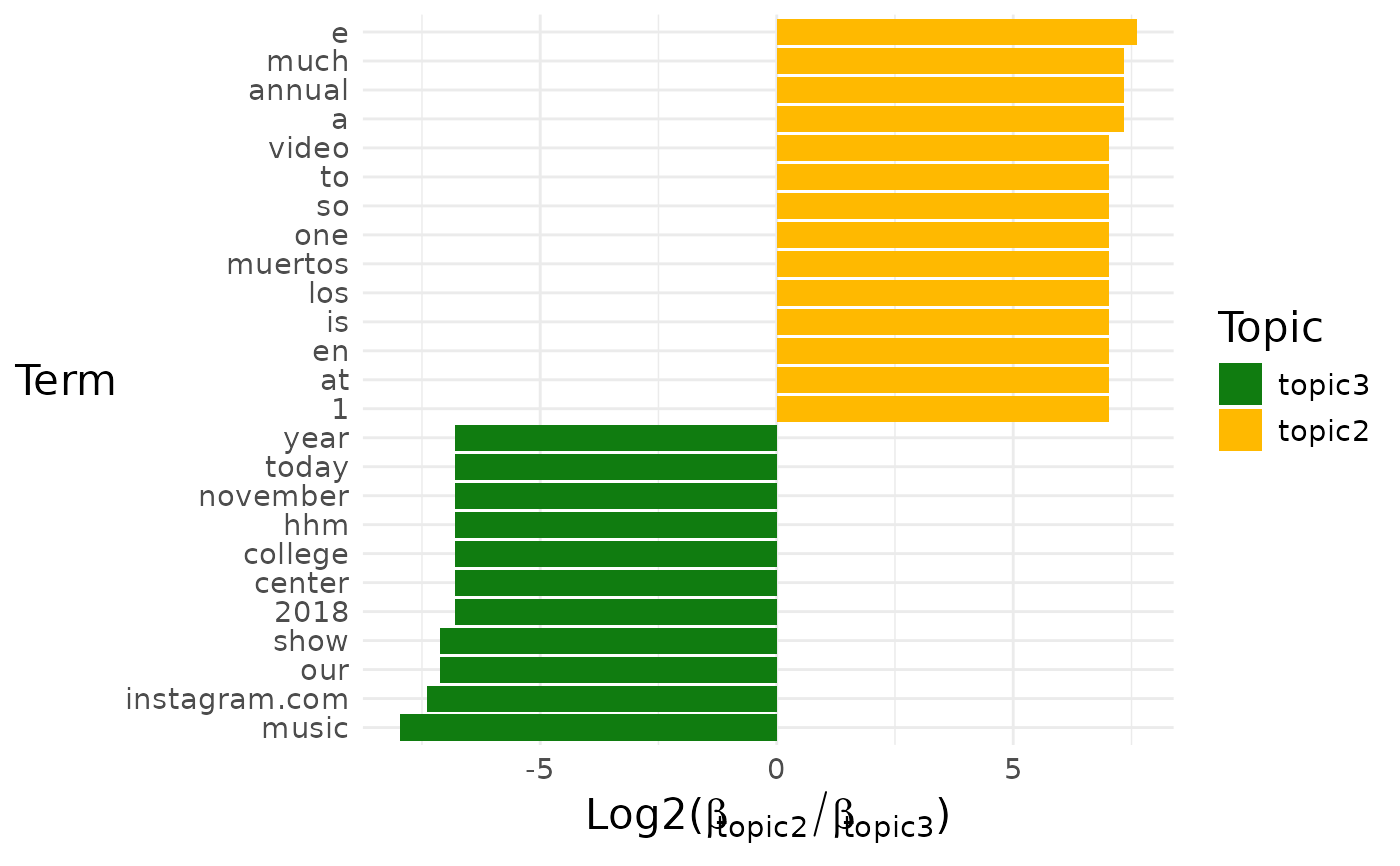 #>
#>